Sturdy Statistics uses special, sparse-coding priors which strongly separate the signal from the noise in your data. Removing irrelevant information allows our models to make more efficient use of labeled data, focusing it on the only the relevant portions of the data. This enables Sturdy Stats models to train more efficiently, extracting more, and more valuable, information from your data.
This plot compares the Sturdy Statistics regression model against a typical L2, or “ridge” regression. The L2 has been specifically tuned for this problem by a data scientist, while the Sturdy Statistics model has been run straight “out of the box,” precisely as a user of our API would. The sample problem shown here has two solutions: some parameters (shown in gray) should be exactly zero, while others (shown in red) should be exactly 5. These correct solutions are marked with gray and red lines. Each row shows results from training the models on progressively larger datasets: the Sturdy Stats model performs far better on 10 data points than ordinary regression does on 45! And this is despite the ordinary model being tuned by an expert, while the Sturdy Stats model is self-tuning and fully automatic.
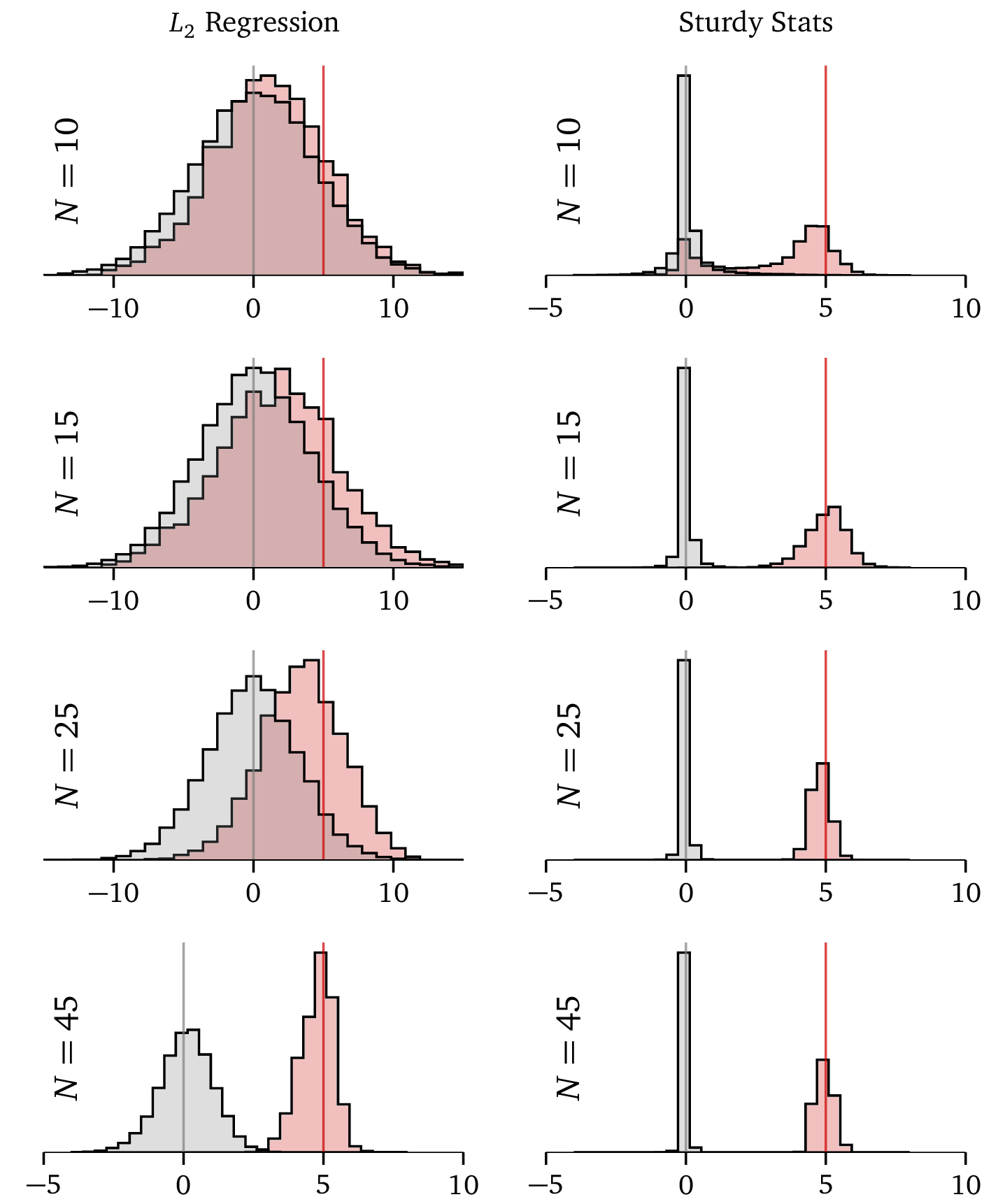
While the ordinary L2 model slowly converges to the correct solution as we add more data, the Sturdy Stats model locks onto it immediately and becomes quite confident, even with just 15 data points. With features like this, Sturdy Statistics automates much of the work of a data scientist. See the detailed description here for more information about this technology.